

今天开始,我们花上几期的时间,给你讲一个比较大的话题:建筑信息编码。
2018年5月1日《GBT 51269-2017 建筑信息模型分类和编码标准》正式执行,很多人还是有一肚子的问号。
● 编码到底是什么?能干什么用?
● 为什么一定要编码?用模型不行吗?
● 编码标准的执行和我有什么关系?未来会影响哪些领域?
即便是对编码稍有了解的人,也对它有两个比较深的误解:
误解一:编码就是给建筑物的构件上「身份证」,给墙、柱、梁、板等物体赋予ID,统计用量时会比较方便。
但当你去翻看《分类和编码标准》的时候,会发现里面还有项目阶段、工作成果、工具、甚至是参与角色的编码,这些可不是建筑构件啊,为什么也要编码?
误解二:编码标准是给软件开发商用的,和普通设计师没关系,只要等软件开发好了直接用就行了,编码会自动附在模型上。
理论上是这样,但越来越多大型企业的项目或海外项目,已经明确要求在提交设计内容的时候按照某某规范进行编码,而软件的「自动编码」功能还遥遥无期,这又该怎么办?
这一个系列,我们就一步一步剥开建筑信息编码这个大洋葱,说清楚它到底是干什么用的,北美三大编码体系和英国的Uniclass是怎么回事,我国的编码体系是什么情况,新出的分类和编码标准该怎么使用,
最后还会说到,面对工程项目的编码需求,我们该使用什么样的工具来完成工作。
好了,废话不多说,BIMBOX开车了。

当我们说编码的时候,到底在说什么?
所谓编码,就是「用通用性的符号来简化某些含义」。人类的语言就是一种编码。
比如,「天上那个早上出来傍晚落下去的金色火球」,就是个很长的含义,英文世界用「sun」这个字母组合来表达它。
中国就用一个圆圈中间加个点来表达它,后来这个符号演化成汉语里的「日」字。

不同地区使用不同的语言,这在人类文明发展的几千年里都没有出现大问题,文明互相接触的时候可以互相学习对方的语言。一个人脑子里同时装下「太阳」、「Sun」、「お日さま」几个符号并不会出现混乱。
但到了计算机发明出来、人类进入数字化时代的时候,麻烦可就出现了。
当我们说建筑信息编码的时候,一个大前提就是用计算机来进行编码。换句话说,就是把自然语言编写成计算机可以读取的数据,这样的数据才能自动进行计算和分析。
所以要说清建筑信息编码,就得先用一期的内容来说说人类进入数字化时代碰到的麻烦,以及我们是怎么解决它们的,这件事还真没想象那么简单。
你可以做一个有趣的试验:在任意文件夹新建一个TXT文档,输入「联通」两个字,保存关闭,再打开的时候,原来的两个字变成了奇怪的乱码。
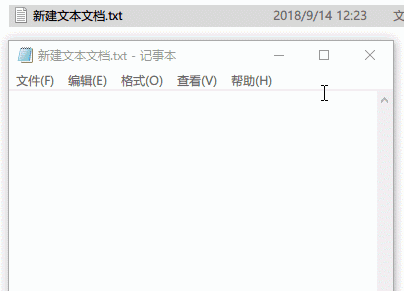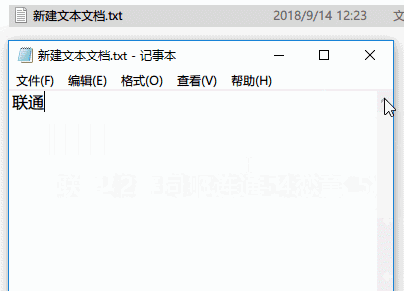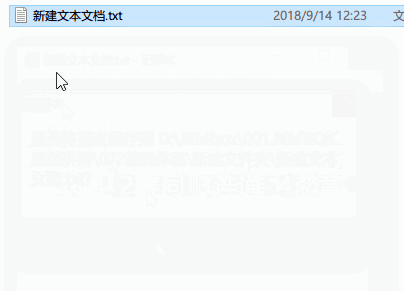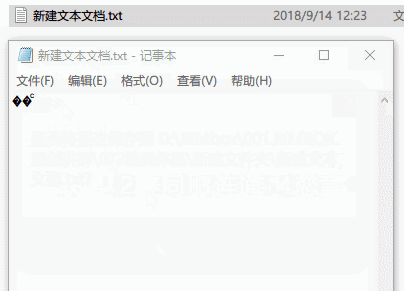
这个诡异的现象,就是人们解决计算机编码问题遗留下来的一个小尾巴。我们最后再来回答这是怎么回事。

从语言到数字
计算机一开始被发明出来是用来做算术题的,它通过内部很多小开关的打开和关闭两种状态,来表达不同的数字和运算规则。
所以计算机只能处理两个数字:0和1。一切数字都必须转化成2进制才能计算。十进制是逢十进一,二进制是逢二进一,十进制的3转化成二进制就是11。

每一个小开关的0或者1的状态,叫做比特(Bit)。
仔细一想,你会觉得有点怪:计算机面对一大串0和1的时候,它怎么知道哪里开始、哪里结束,哪里断开呢?比如下面这串二进制数字,如果把它理解成一个数,换算成10进制就是72:
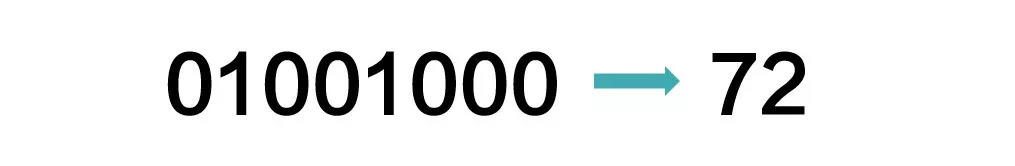
而如果把这串数字从中间断成两部分,就分别表达4和8两个数:
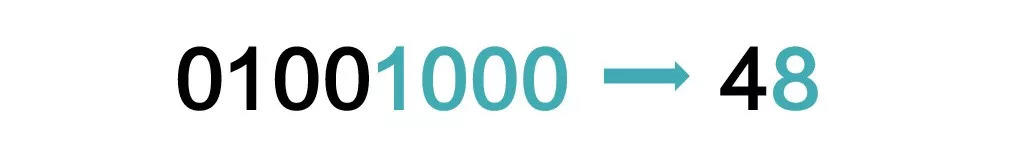
为了解决这个问题,人们就强制计算机每次都处理8个连在一起的数字,不能断开,这8个比特组成的一个最小计算单元,就叫字节(Byte)。

你可以把一个字节看成一个编码状态,每一位有两种可能(0和1),一共8位,不同的排列组合可以表达出2的8次方=256种状态。

人们发现,这么多种状态不仅可以表示数字,还可以把英文字母和一些特殊符号囊括进来。这样一来,计算机就不仅可以处理数学问题,还可以处理文字了。
不同字节状态具体代表哪个字符,需要统一口径。于是1968年,美国国家标准学会就制定了一套标准,规定所有字节第一位统一为0,只用了八位数的后七位,也就是2的7次方=128种组合。

前32种是控制字符,让计算机执行一些特殊指令,比如00000000表示空字符,00001010表示换行。
从第33种组合开始,后边的字符分别代表英文字母、数字或一些特殊符号。比如01010011代表S,00110000代表数字0。
这样,英文单词Sun就可以变成三个8位数的字节,被计算机理解了。

这套标准叫做美国信息交换标准码(American Standard Code for Information Interchange),简称ASCII。
后来,电脑从美国传到了其他国家,像法国或者德国这些国家的语言里还有一些非英文字母,ASCII编码方案就不够用了。
不过没关系,ASCII第一位统一都是0,只用了256种组合中的前128种。这些国家就在ASCII的基础上,从第129种组合开始扩展自己的编码体系,把新增的符号定义为1开头的字节,这样就把ASCII的容量扩充了一倍。
这些国家扩展的规则是不一样的,同样一个字节,在阿拉伯或者俄罗斯的ASCII扩展中代表不同的字母。
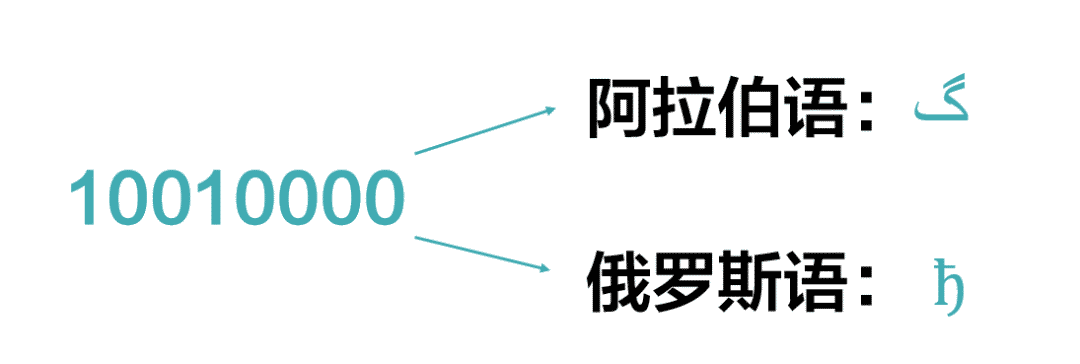
大家基本上是各用各的标准,有得用总比没得用强,也还算是开心。
但也有其他人不开心。
比如中国,常用汉字有几千个,加上生僻字和少数民族语言符号有几万个,区区256种组合怎么够用?
没办法,我们只好自己开发一套编码规则,不使用8位的单字节,而是使用16位的双字节来表达一个符号。这样我们就有2的16次方=6万多种组合可以用了。

中国的编码标准从最早的GB2312,一直发展到最新的GB18030,从几千个常用汉字扩充到几万个符号。
为了解决中英文混合问题,GB系列编码也必须向下兼容ASCII编码才行,
GB编码标准规定:凡是以0开头的字节,都被认为是ASCII编码中的英文字符,凡是以1开头的字节,就告诉计算机还没完,得把下一个字节也算进来,组合起来表达一个汉字。
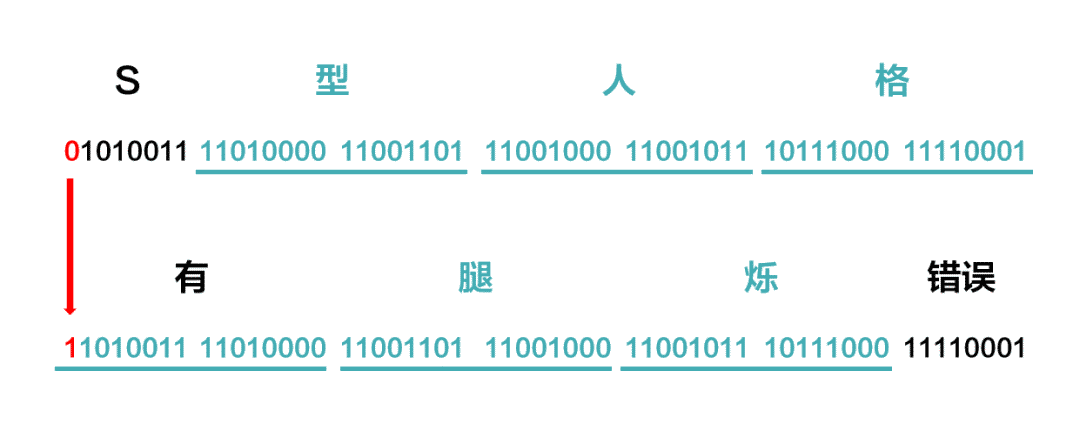
比如「S型人格」编码就是下面这样:

不过,这种双字节中文字符和单字节英文字符并存的编码方式,会带来一个新麻烦:使用GB系列的编程人员需要万分小心,一旦弄错了一个字节,很可能后边跟着的所有文字就全错了。
比如「S型人格」的二进制编码,如果把第一个字节中的第一位0替换成1,其他不变,即便只错了一个数字,也会导致一串编码全部错误。
这种情况在单字节的ASCII里是不会出现的。
如果说编程上的容错性可以通过我们辛勤的本土工程师来解决,那更大的麻烦还在后面。

霸气的「终极语言编码」
到这个时候,世界上的编码体系已经很混乱了。
非英语国家对ASCII码用各自的方法扩充,同样的字节代表不同的符号,中国这样的国家还用单双字节混编,甚至大陆和台湾的编码规则都互相冲突。
这对于跨国软件公司和互联网发展都是非常不方便的,使用软件或者访问网站,必须事先安装对应地区的编码系统,否则就会出现乱码。
这时候国际标准化组织ISO站出来说:都别闹了,我来制定一个大一统的编码规则吧!
这套编码规则俗称Unicode,囊括了地球上所有文化的符号。因为各地区的编码已经出现了冲突,大一统编码已经不能兼容不同国家现有的编码了。
ISO的做法很暴力:除了对ASCII向下兼容,其他的编码统统废除,重新编。
16位的双字节编码只能组合出6万多种可能,要做到大一统也不够用。没关系,再加位数,加到32位的四字节编码,排列组合高达42亿种。这下用到宇宙文明统一也没问题了。
不过,旧麻烦的解决总是会带来新麻烦。
首先就是储存效率问题。
对于欧美国家来说,本来用一个8位字节能解决的事,为了兼容其他语言,硬生生的要用双字节甚至4字节来编码,比如ASCII中字母S的编码是「01010011」,到了Unicode里就要把前面的空位用一串0补足。

这样,本来用1个G能储存的文件,变成4字节的Unicode码之后就会变成4个G。
更大的问题是网络传输问题。
在Unicode编码发明的时候,网速还是很慢的。如果一次传输4个字节,效率就是单字节的四分之一。
想想你花钱买了20M的宽带,因为换了个编码系统,变成了5M的速度,搁谁也不干啊。
所以Unicode编码在当时遭到了英文国家的强烈抵制。
为了解决这个问题,人们又发明了Unicode编码转换格式(Unicode Transformation Format),简称UTF,来规定Unicode编码的储存和传输方式。
它分为UTF-8、UTF-16、UTF-32等等,顾名思义,UTF-32表示一次传输32位、4个字节,UTF-8就表示一次传输8位、一个字节。
其中,UTF-8效率最高,最为常用。
既然UTF-8是一次传输一个字节,计算机怎么知道当前这个字节是完整表达了一个含义,还是后边还跟着其他字节呢?
UTF-8是变长度编码,根据符号在Unicode中所在的编码位置,定义了不同的字节长度模板:
如果一个符号在Unicode码中占前127位,只需要一个字节就能表示,对应的二进制是0开头的8位数字,那就直接传输这个字节,并在这个字节结束,不需要前面再补0了。
也就是说,英文语言使用UTF-8和ASCII是一模一样的。

位数增大,一个字节不够用了,就套用这样一个双字节模板:第一个字节以110开头,第二个字节以10开头,告诉计算机,这两个字节需要组合起来共同表达一个符号。下图中红色的部分就是强制规定的模板数字。
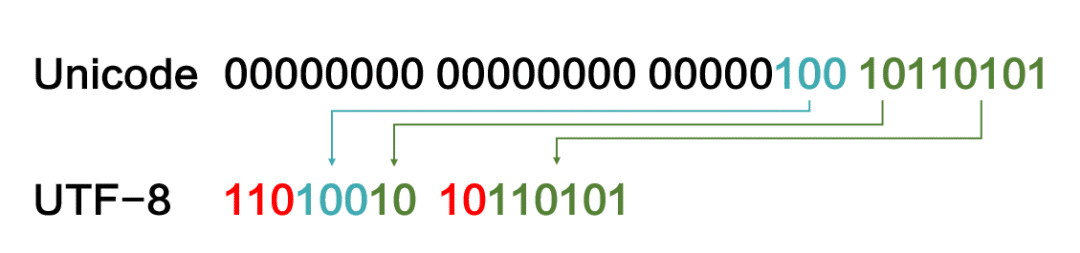
位数继续增大,两个字节也不够用了,就再套用一个三字节模板:第一个字节以1110开头,后面两个字节还是以10开头,告诉计算机,这是一个三字节组合的符号。
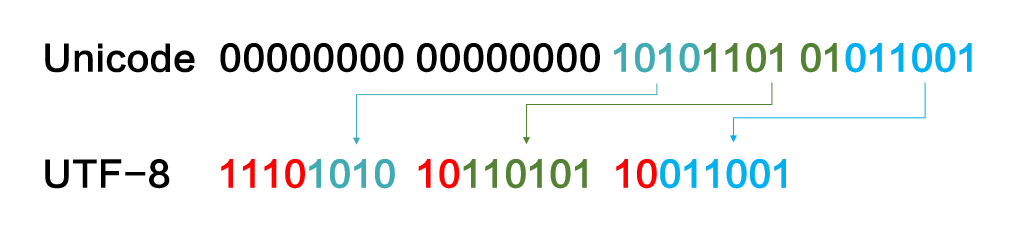
以此类推,四个字节的模板就是:第一个字节以11110开头,后边再跟着三个以10开头的字节。
这样,我们就解决了不同语言之间编码兼容的问题,又解决了低位数编码的传输效率问题。
当一个文件以英文为主的时候,UTF-8的效率非常接近ASCII。不过对于中文来说,汉字用GB码只需要两个字节,到了UTF-8里却需要用3个字节来表达(因为上图中红色的模板数字占去了4+2+2=8位),所以纯中文的网站用UTF-8比用GB码传输起来效率要低一些。
但前面我们说过,GB码中英文混排的时候,会因为弄错或者丢失一个字节,导致后边的所有文字全都错误。而UTF-8在多字节组合的时候有一套严格的模板,中间一个字节出现了错误,乱码不会扩散,比GB码多了容错性的优势。
此外,使用UTF-8,其他国家的人不需要安装中文编码规则,也不会出现乱码。所以国内的新网站更偏爱使用UTF-8。
因为UTF-8和GB码两者是完全不兼容的,所以一些老牌中文软件和网站出于转化成本的考虑,还是沿用GB系列的编码。
说到这儿,我们就能解释前边那个记事本「联通」两个字乱码的现象了。记事本在打开一个文档的时候,不会问你是用什么格式储存的,而是通过你输入文字的代码来「猜」它的编码格式。
在我们输入中文的时候,记事本默认使用的是GB编码,我们看「联通」两个字对应的GB码:

注意看红色部分,是不是和UTF-8的双字节模板正好一模一样?所以当你默认保存再打开的时候,记事本通过这两行代码,猜测这个文档用的是UTF-8格式,而UTF-8和GB编码是不兼容的,于是就出现了乱码。
你可以试试,在存有「联通」的记事本文件另存的时候,选择用UTF-8格式保存,或者多打几个字,再打开就不会出现乱码了。
好了,总结一下今天说到的几个知识点:
● 计算机无法理解自然语言,需要转化成二进制编码;
● 英文和数字在转化的时候效率最高,只需要用到8位的单字节编码ASCII;
● 不同地区各自设计编码,迟早会在交流中遇到问题,大一统编码势在必行;
● 编码规则中,某一个符号必须严格对应一个二进制代码,否则就会出现混乱;
● 新编码规则不占用旧编码的代码,且保留原来的一一对应关系,它就是向下兼容旧编码的;
● 新编码如果不兼容旧编码,就会产生替换成本,从而引发一系列历史遗留问题;
● 为解决一个麻烦创造新的编码,经常也会带来新的麻烦;
● 编码的简洁高效与可扩展性,往往不可兼得。
下一期开始,我们的建筑信息编码就要正式登场了。你不妨先思考一个问题:
如果编码只需要考虑语言兼容的问题,为什么光是北美地区就先后出现了Masterformat、Uniformat、Omniclass三种建筑编码体系?比起语言编码,建筑编码是不是有更复杂的问题需要解决呢?
欢迎你把疑问和对编码知识的见解留言给我们,我们会把你的高见和我们的回答补充到后面的连载内容里。
有态度,有深度,BIMBOX,咱们下次见!








暂无评论
要发表评论,您必须先 登录