

今天要给你聊一个比较大的话题:建筑业人工智能。
对于建筑业的未来,我们经常能听到这样的畅想:
一位设计师把头盔戴到几位业主的头上,业主眼前出现了几十种初步设计方案。他们选择了最喜欢的那个方案,紧跟着一系列的分析报表和经济指标出现在眼前。几位大佬一商量,就这个了!
于是人工智能后台开始根据这个方案,自动进行结构设计、机电设计,紧接着数据从后台传到工厂,自动加工构件,由机器人自动装车送到现场。工地上只有几个工程师指挥着机器人,把预制构件搭建到一起,其余部分用3D打印技术自动完成,一幢高楼就这样拔地而起。
不知道你听了这个故事有什么感想啊,如果BIMBOX也只是和你畅想一下未来,顺便给你一点失业的危机意识,就有点太肤浅了。
今天我们尝试来说几点更贴合实际的内容:
➤人们对人工智能存在哪些误解?
➤人工智能可以做哪些事?哪些事是人工智能做不了的?
➤人工智能可以对建筑业带来哪些机会和危机?
人工智能,英文名Artificial intelligence,一般缩写为AI。
超过90%的人对它存在着非常深的误解,认为所谓人工智能,就是很聪明、会像人一样思考的机器,尤其在2016年AlphaGo战胜了李世石,很多人都觉得人工智能全面替代人类工作的时代已经到来了。

「让机器像人一样思考」,不仅是普通人对人工智能的直观感受,也是一开始科学家希望做的,可惜这条路在上个世纪就宣告失败,今天的人工智能,走的是一条完全不同的路线。
我们先通过一个例子说说最早的人工智能所模仿的、人类的思考方式。
今天,一个小学生都能告诉你,太阳系所有行星绕着太阳做椭圆周运动,但在古代,人们并没有能飞上天的各种设备来直接观测,他们只能通过观察其他星球的运动轨迹来猜测太阳系的样子。
通过规则的日升日落,人们很容易能想到,太阳应该是绕着地球转的,这最符合人们的直觉。
而其他星球就没这么简单了,比如金星,从地球上看它的运动轨迹就是这个鬼样子:
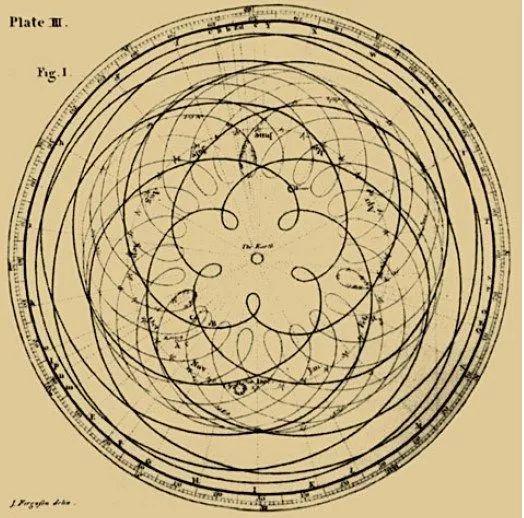
这张图是人们长年累月的观测金星的位置,把大量的点连成曲线得到的。这个过程就是获取数据。
下面,人们需要对数据进行分析,然后建立一个理论模型来解释它。
公元一世纪,托勒密提出了「地心说」,用来解释金星的运动轨迹。
很多人认为老祖宗们相信地心说这么长时间,很愚昧,其实不然。这个模型很好的吻合了数百年人们的观测数据,而且能很精确的预测行星的位置。
不过,托勒密的理论模型最大的缺点就是太过复杂,它需要用40多个圆形嵌套在一起才能够描述行星的位置,计算起来特别费劲。你可以通过这张图来理解不同理论解释行星运动的区别:
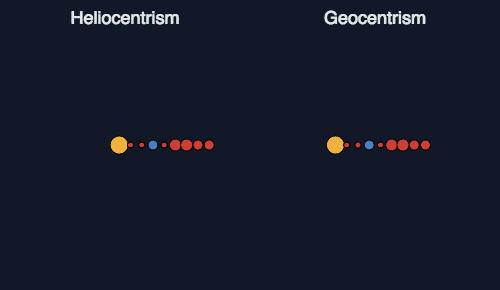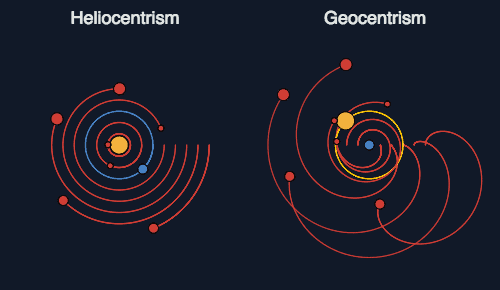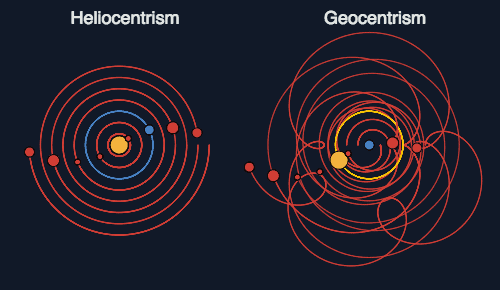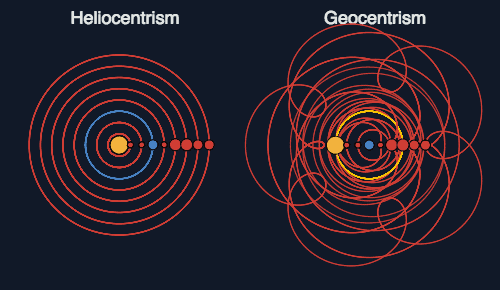
后来哥白尼提出「日心说」,并能够取代地心说,也并不是因为它更接近真相,而是它可以用更简单的计算达到同样的预测效果。
不过由于哥白尼和托勒密一样,都是使用正圆形来描述行星的运行,所以他的理论也还是不够简洁,只是把需要嵌套的圆的数量从40个减少到10个。
再后来,开普勒发现,如果换做椭圆而不用正圆,那就不必嵌套多个圆了,只需要一个椭圆就能完美的解释和预测行星轨迹。于是,日心说又前进了一大步。
这时候人们还是不知道为什么行星会沿着椭圆运动,所有理论都是根据数据凑出来的。直到牛顿提出了万有引力定律,才解释了天体的椭圆形运动规律。
再到后来,爱因斯坦的相对论又进一步消除了水星轨道的误差。
从地心说到日心说,再到牛顿和爱因斯坦的理论模型,这个过程代表了人类解释世界的思考模式:通过观察获取数据,然后猜出一个模型,缝缝补补的凑合着用现有的模型,直到有更精确、更简洁的模型出现。
人们把这种思维模式称为机械思维。这种思维方式相信世界一定有一个确定的理论来解释一切,我们的终极目标就是找到这个理论,然后一劳永逸的用它来预测未来。
关于人工智能,一开始计算机学家的想法和现在的人工智能门外汉是一样的,也就是「机器要像人一样思考才能获得智能」。

不过,这种尝试只持续了十几年,人们在几个不同的领域尝试实现人工智能,都遇到了各自的瓶颈,其中包括语言翻译、语音识别、图像识别,也包括下围棋。
咱们用语言翻译这个领域来举例。
人类的思考模式是:学会单词,然后学会语法,再根据语法把单词拼成句子。学单词就相当于「获取数据」,语法就相当于「理论模型」。
比如,你学会了「Good」和「Morning」两个单词,有人告诉你,把「Morning」放在「Good」后面,就是「早上好」的意思。
你似乎把语法搞明白了,但如果你又知道「You」这个单词是「你」的意思,那你一定会想当然的认为英文的「你好」应该是「Good you」。
这种蹩脚的翻译结果正是早期的人工智能经常拿出来的。
于是人们就想,继续告诉计算机更多的语法规则,直到它像一个人一样彻底理解了一门语言的各种语法。
不过这也不行。
比如中文这一句:「我想起来了」。你既可以把它理解为「我想起某件事来了」,也可以理解为「我想从床上爬起来了」,到底该怎么翻译,答案不在句子内,而是在句子外的上下文。但你根本没办法把可能出现的所有上下文提前输入到计算机里。
计算机的计算速度确实会越来越快,但语言翻译的规则模型太过复杂,不可能提前把这些规则一条一条告诉计算机。真正限制人工智能发展的,不是它本身的计算速度,而是人类对规则的输入速度。
这时候,有人开始思考,能不能换一种方式:不事先告诉计算机具体的语法规则,而是直接硬碰硬的进行整句的翻译呢?
他们的思路是这样的:人工智能可以不去理解「Good」、「Morning」这两个单词,也不理解背后的语法规则,而只是把「Good Morning」直接翻译成「早上好」。世界上有多少个整句中文,就把这些句子对应的整句英文统统记录。
你可能会说,这不就是穷举法嘛,这办法也太笨了吧!
一开始人们也非常反对这种笨办法,不过没用多长时间,人们就得到了答案。
2005年2月,全世界的机器翻译专家在美国齐聚一堂,交流各自的研究进展,一家从来没从事过机器翻译研究的搜索引擎公司:Google,也参加了这次会议。

本来人们没怎么关注Google,以为它是来玩票的。评测结果一出来,所有人都大吃一惊,Google翻译的评分排名第一,落下第二名将近一代人的水平。
大家请来Google翻译的负责人,问他秘密是什么。秘密说出来一点都不神秘,Google使用的就是几年前被大家瞧不起的笨办法:让计算机自己在海量的中英文对照中,直接学习整句的翻译。
只不过,长年开展搜索业务的Google有一个先天性优势:它手中握着大量的中英文对照数据,比其他研究组织多了上万倍。
2005年被人们称为「大数据元年」,人们第一次见到了数据的魔力。
有一个叫「中文屋子」的故事:
一个人坐在一间屋子里,手里有一本非常厚的参考手册。有人通过门缝递进来一张纸条,上面写着一行中文字,屋子里的人根本不认识中文,他需要做的只是翻开手册,找到那句看起来和纸条上的文字一样的话,然后把对应的中文答案照着样子抄下来,再递出门去。
外面的人看到里面的人做出回答,以为他肯定是懂中文的,而实际上,屋子里的人从头到尾既不知道自己看到的是什么内容,也不知道自己回答了什么。
这个故事说明了新一代人工智能的思维方式:放弃明确的因果理论,而只关注事件之间的相关性,从大量的数据中直接得到答案,即使不知道背后的原因。
实际上找到「数据背后的理论模型」效率是很低的,还得看运气。人类花了几千年才等到了牛顿定律和相对论,而下一个突破性的基础理论又不知道要等到什么时候。
目前,「数据驱动论」已经在各个领域全面碾压了「模型驱动论」,成为了人工智能研究的主流方法。
比如,AlphaGo并不理解围棋的套路和技巧,不了解对方下某一步棋的目的。在每一次对方落子后,AlphaGo都会把当前黑白子的布局看做一种「状态」,根据过去下过的上百万盘棋局,找到胜率最高的下一步状态,然后走出这步棋。
当然,围棋非常复杂,棋盘上所有黑白子的排列可能性加起来,比整个宇宙中所有的原子还多,所以不可能在下棋的过程中去暴力搜索,而是需要在平时不停的训练和学习。
这个「机器学习」的过程原理讲起来比较复杂,我们换个领域举个例子你就明白了。
在图片识别领域,传统的智能思维是这样的:给计算机描述一只狗的全部特征,比如1米左右长,毛茸茸,伸舌头,等等。等它掌握了这个方法之后,再去识别图片中的狗。
这条路显然是走不通的,因为有的狗毛很短,有的狗没有伸舌头。
而数据思维的方法是,完全不告诉计算机「狗」是个什么东西,而是扔给它海量的图片,让它判断图片上的是不是狗,再通过事先的答案或人为干预来告诉它结果是否正确。
一开始它的判断基本上和瞎猜没区别,但随着不断迭代,得到的答案越来越多,它的识别度也就越来越高。
注意,即便这个程序已经可以精确的识别出狗来,它还是不知道真正的狗是啥样的。它得出答案的理由很可能是「图片左边39%的区域有黄色像素点,中间有两个区域的深棕色像素点,这样的图在历史数据中,有97%的概率应该输出答案为狗」。
从这个例子,你应该能理解人工智能注重「相关性」而不是「因果关系」的原理了。利用相关性,最大的好处是随着学习和迭代的次数增加,人工智能可以做到的事就越来越精准。
所以,只有喂给学习程序的足够多的数据,才可能实现人工智能。这也是为什么早期的人工智能发展会那么缓慢,因为那时候还没有互联网的爆发,没有一家公司手里有海量的数据供机器学习。
人工智能和大数据是硬币的正反面。想要做人工智能,手里必须有大数据才行。
大数据除了要「大」,还有两个必须具备的特点。
第一是多维度。
比如我们经常会说,天气闷,要下雨。「天气闷」和「下雨」是相关性很高的两件事,但如果只有这一个维度的话,还是会经常错判。但如果把气压信息、云图信息等其他维度的信息都加入到判断体系里来,那判断出下雨的准确性就很高了。
第二是被动关联。
所谓被动关联,就是人们在自主行动的同时,下意识而不是故意的留下数据的痕迹。
比如2013年,百度公司发布了《全国十大吃货省市排行榜》,利用的就是人们的搜索数据。福建人最关心的是什么虫子可以吃,而宁夏人居然最关心螃蟹能不能吃。
百度获取的数据是人们在搜索过程中,不自觉的贡献出来的。
如果一家公司去大街上发调查问卷,人们很可能不愿意填写关于虫子和螃蟹的真实想法,得到的数据也就不真实了。
有个故事能说明大数据的好处:
美国一家大型连锁百货店塔吉特,用大数据分析用户的行为,利用多维度和关联性数据猜测他们的身份并给每个人推荐货物。
一天,一位中年人闯进了塔吉特经理办公室,责备他们公司给自己上高中的女儿寄来了母婴用品的优惠券,这不是鼓励女儿怀孕么?经理赶忙道歉,说我们并不认识每一位顾客,只是用大数据来分析,怀孕的女性会在不同时期表现出不同的购买行为。
不料过了几天,那位父亲又找上门来,给经理道歉,说他和女儿谈了,她真的怀孕了。塔吉特对用户的了解,比她的父亲还要多。
如今的互联网之争,在某种程度上也就是数据之争。
所以你会看到,当今很多的人工智能产品都出自于Google或者百度公司。许多互联网公司即便做不了搜索引擎,也要做免费的浏览器,收集用户的搜索数据。
2015年,小米公司仍在只卖手机、而且是亏损状态,在融资时被国际知名风投机构估值为450亿美元,而对于手机出货量与小米差不多、还多年盈利的联想公司,估值却只有100亿美元。

风投公司的经理们当然不是傻子,小米比联想多出来那么多的价值,就在于它从智能设备中获取的大量用户数据。
我们再回到建筑业,回看一开始人们对未来的设想。
如果按照传统的人工智能研究方法,我们当然可以胡乱畅想:自动设计,自动生产,自动施工——因为机器会越来越聪明嘛。
但看完前面的内容你知道,这种更符合直觉的思路是已经被人工智能专家们放弃的路线。
当前,确实有很多的技术可以在设计、生产和施工环节中帮助到我们,比如自动翻模、焊接机器人等等,但它们本质上是通过编程来缩短某项工作的时间,提升效率,并不是人工智能。
人工智能不是遥远未来的事物,它确实正在深刻改变着我们的世界,也带来一些失业的危机。比如,已经有人工智能律师、人工智能记者,甚至是人工智能医生被研发出来。
不过这些行业有一个共性,那就是行业里有大型公司或机构掌握着大数据。
如何判断一家公司做的是不是真的人工智能,最重要的标准就是它是否有海量的数据,并且这些数据是多维度的、有关联性的。
反观建筑业,在BIM普及之前,收集足够喂养人工智能的海量数据几乎是不可能的。以前建筑业所有的数据都存在于图纸和文档里,基本不能用来分析和机器学习。
而BIM作为收集建筑业数据的绝佳入口,到今天也只是在一部分项目中使用,数据的广度和维度还远远不够。
尽管有很多公司会说自己拥有建筑业大数据,但数据这东西可真不是喊喊就有的,否则像联想那么大的公司,也肯定能喊出不少数据来,估值也不会比小米低那么多了。
目前不太可能有一家企业在没有数据喂养的情况下,做出一款「全自动设计管线综合」的软件来,除非咱们建筑业能突破IT行业对人工智能的探索。所以你并不需要太担心,一些看上去比较枯燥的设计工作,并不会在短期内被人工智能替代。
另一方面,大数据的缺失也正是我们这个行业所面临的前所未有的巨大机会。BIMBOX猜想,有几个方向将会成为建筑业人工智能领域的风口。
第一是创造大数据入口。
人工智能的核心是拥抱不确定性,目前建筑业即便是和数据最贴近的BIM技术,也还是遵循确定性思维。我们建立确定的模型,输入确定的信息,输出确定的图纸。
人工智能需要的大数据,比建筑物本身的数据要复杂得多。比如「设计师在挪动一根水管的时候更多的往左偏还是往右偏」、「地铁中更多使用方一些还是扁一些的风管」这样的数据,就是可以用来喂养人工智能的好数据——它不需要知道为什么,只需要知道怎么做成功的概率更大。
而如果有一个平台能让使用者无意识的贡献这些数据,并把它们收集起来,将会是一个强大的数据入口。
第二是用数据喂养智能巨兽。
尽管我们说建筑业人工智能暂时不会到来,但它迟早会到来。
智能未到,数据先行。真正懂得借助深度学习算法,用数据喂养和训练人工智能产品的企业,无疑将会抓住时代的脉搏。
这样的企业并不一定崛起于行业之内,像阿里、腾讯这样的数据大鳄,也非常有可能扮演这样的角色。——实际上他们已经在行动了,这个话题我们改天再聊。
第三是用数据关联性进行企业级服务。
人工智能或大数据技术的应用不一定是一个To C端的产品,企业级的分析和咨询服务也是一个很大的应用市场。
前面我们讲到的美国百货商场塔吉特,就是传统企业应用大数据的典型。
未来的建筑业,会有大量的企业需求数据分析和智能服务。
需要再次强调的是,智能时代的咨询和分析服务,不再是传统的「大胆假设,小心求证」的确定性方式,而是跳过逻辑,直接用数据之间的关联性说话。
比如:「根据这个月贵公司员工的Navisworks软件打开率,分析得出近期项目的造价预算可能出了问题」——没人知道背后的原因,但结果是准确的。这是只有掌握大量数据的公司才能提供的服务。
关于建筑业的大数据和人工智能,我们今天还有很多东西没有展开讲,如果你希望了解更多,或者有自己的见解,也欢迎给我们留言。
这一期就说到这儿,希望能给你一些帮助。有态度,有深度,BIMBOX,咱们下次见!









暂无评论
要发表评论,您必须先 登录