

提到BIM中的「Information」,也就是信息,也许你马上能想到,点击模型中一个构件,就能看到它的尺寸大小、属性、成本等等,但信息的范畴还远远不止于此。
咱们今天就来说说信息的本质。
首先需要注意的是,信息不等于数据。
无论你需不需要,数据都存在,只不过存在形式可能是离散的。而信息,是为了特定的目的,回答特定的问题,把数据以特定的方式组织到一起。
最重要的是,首先得提出问题,才能得到信息。
软件把数据组合成有用的信息,有三个重要的手段,它们是结构化、可视化、和关联性。
有点儿晕是吧?举个身边的例子给你说清楚。
假设你绝大多数的消费都用支付宝,那你点开账单,会看到一长串的消费记录,这些消费记录平躺在那里,你什么信息也得不到。
下面我们开始提问题。
如果你问自己,10月份我花了多少钱?这个问题的答案很容易得到,点击一下按月份筛选就知道了。
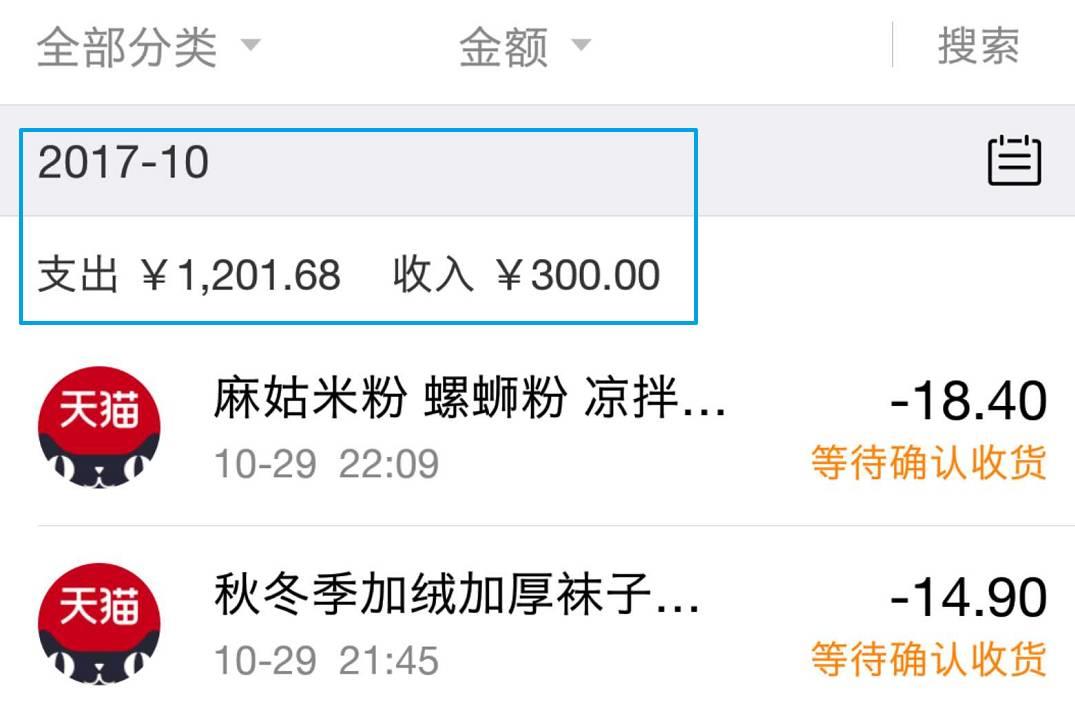
软件在这背后做的工作,用的就是数据处理的第一个手段,结构化。说白了,就是把数据编成一张表格,回答这个问题需要两列的表格,第一列是时间,第二列是金额。
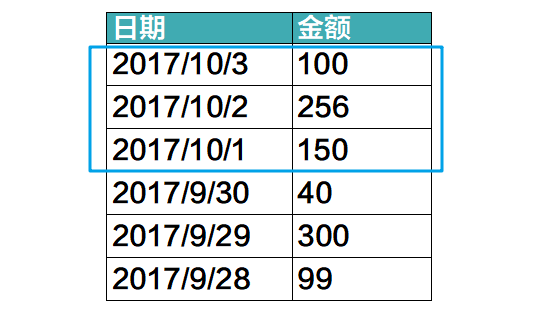
有这么一张表,你就能提取任意一个时间段的总消费金额。当然,这张表格你是看不见的,编表格这个工作支付宝帮你做了。这张表格只有从上到下一个方向,它是一维的。
如果你想进一步追问,10月份我花了多少手机费?
要回答这个问题,一维的表格就不够用了。你得在表格上加一个横向维度,变成二维的表格。这样你就能分别按时间和按类别来筛选出金额,再求和得到答案。
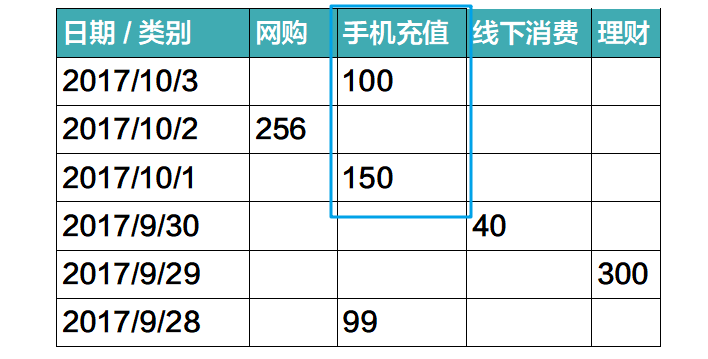
当然这个工作也由支付宝代劳,你需要点击按类别筛选,就会看到答案。

你要是再想从10月份的手机费里找到更精确的分类,支付宝就没再提供这样的功能了,但你能想象一下,还需要再加一个维度,让它成为一个三维的表格才行。
表格上每加一维度,你能得到的信息就越精确。这些互相垂直的维度,也就是BIM里经常说的5D、6D等等。
支付宝提供给你的,就只有上边说的这几个维度。但作为产品背后的公司,却可以收集非常多维度的数据,比如年龄、地区、性别等等,它可以把海量的数据加工,得到更高维度的信息答案,比如「北京中年男性更喜欢在秋天购买什么东西」?这就是大数据挖掘了。
说完了结构化,咱们说说数据的可视化。
下面,你想进一步问个问题:「我今年是花钱越来越多,还是越来越少?」
当然,你可以把每个月的消费记录都看一遍,但这样很花时间。换一种方式,点击一下消费趋势按钮,一条曲线就直接呈现在你面前了。
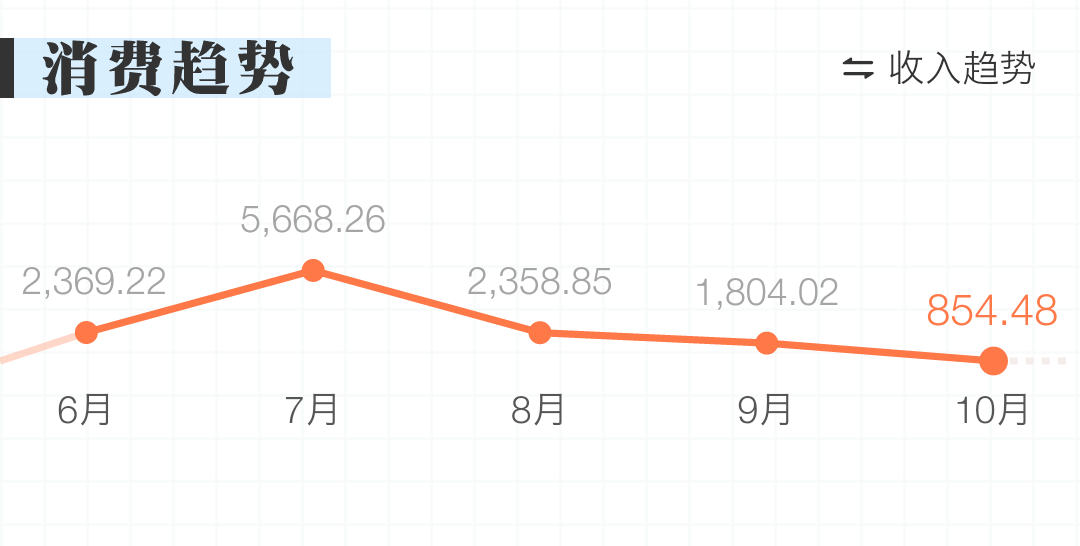
这是软件帮助你进行统计计算后得到的走向图,它的背后还是表格。但你不需要看见这张表,甚至不需要看任何数字,是不是一目了然得到答案了?
同样,你可以用饼状图来直观的回答「我是线上消费多还是线下多」这样的问题。
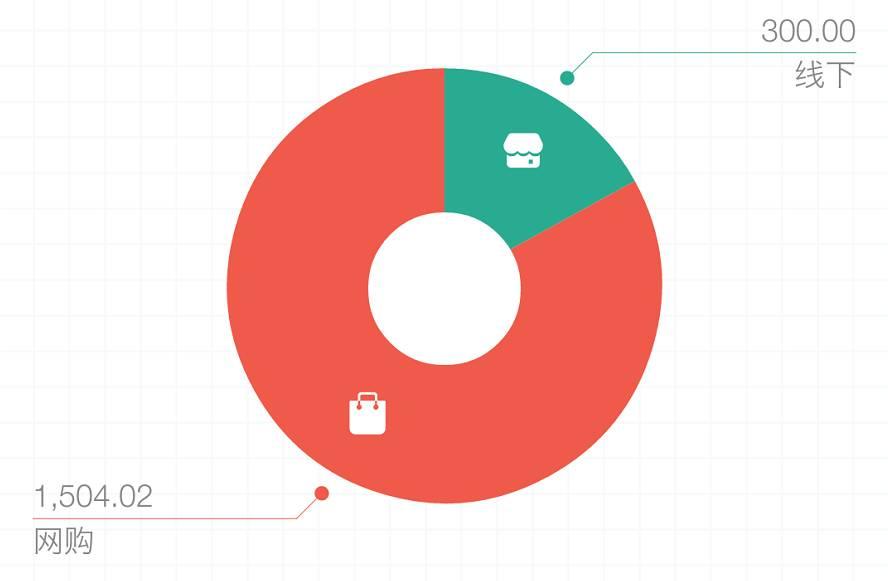
不需要人脑计算数据,直接通过图形得到答案,这就是可视化带来的效率提升。
最后说说关联性。
首先,关联性能提供便利,减少输入工作。
你使用支付宝,实际上没有单独花时间记账,却能免费得到一个账单。随着你每次消费,软件会自动把时间、金额、消费类别等数据记录下来,供你随时调用。
关联性的另一个作用,就是信息可追溯。
比如老婆问老公,你这一年怎么攒不下来钱?
这老公要是是把账目写在本子上,今天支出500,明天支出800,那这一年下来可就说不清楚了。
在支付宝里,两口子可以点开每一笔支出,每一笔消费数据都关联在购买记录——甚至是物流信息、收货信息上,老公不能随便编出一项开支,老婆也没法否认开支,对于总支出的金额也就不会扯皮了。
你想改动信息背后的某一项数据,会有其他的数据跟着改动,甚至有的数据根本不能单独改动,这可以让人通过一个明显的信息错误来发现另一个隐藏的信息错误,这也是关联性的作用。
咱们来总结一下从数据到信息的特征:
➤数据一直都在,软件不会凭空创造数据,即便你不用支付宝而使用现金,你每次的消费数据也存在不同的商家那里,只不过你想重新组织它们会花更大的成本。
➤信息不是天然存在的,要把数据组织起来,才能「挖出」信息。特定的软件只会提供特定的组织方式和维度,没有软件是万能的。
➤生成信息不一定靠软件,你可以用纸笔记账,但你想组织数据挖掘出信息,会花大量的时间,软件的作用是用关联性、结构化和可视化的方式,提高获得信息的效率和准确性。
➤在得到信息之前,你一定要先问一个问题。如果你提不出问题,除了得到看起来比较炫的图形,数据对你来说就没有意义。
到这儿,你对信息是不是有些新的认识了?
咱们继续聊回到BIM中的信息,它同样符合上面说的特点。咱们来举几个例子说明。
比如在规划阶段,你用概念体量创建了这么一个异形的楼,按照标高来分割楼层。除了出几张炫酷的渲染图,体量在模型层面的作用就结束了。

但你可以问这样一个问题:如果我想让这栋楼的商用面积和居住面积大体相等,该怎么划分楼层?
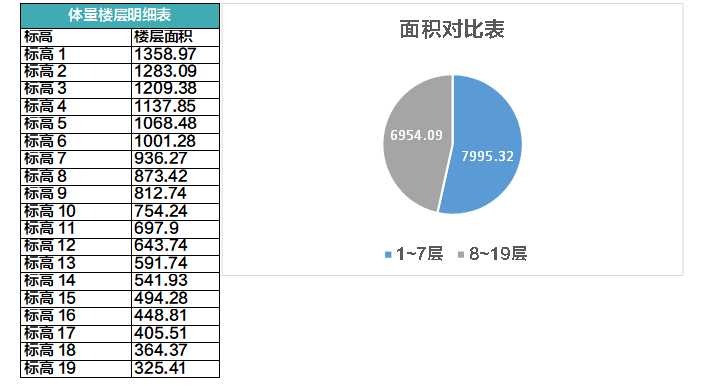
这时候你可以通过明细表统计一下体量楼层的面积,这一步是数据结构化。

不过还是没得到你想要的答案,下一步,你可以把结果导出,通过简单的公式计算,在Excel里获得这样的图表:
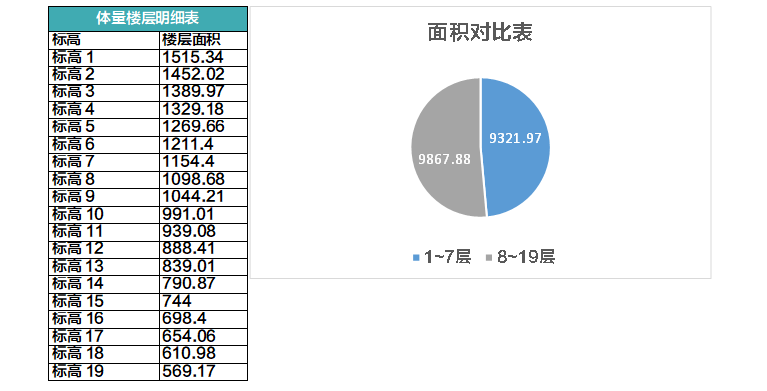
答案是不是马上就得到了?这一步是数据可视化。
后来方案变更,这个体量的形体发生变化,每一层的面积也变化了。传统的设计方式,你还需要把每一层的面积单独算一次,重新做表格;而在BIM里,这一步的工作由软件代劳了,随着形体的变化,你可以直接无缝得到这张新的图表,楼层划分方案就需要重新调整了,这就是关联性。
再举个例子,比如你做好一栋建筑,画好了门窗之后,不提出问题的话,就没有什么信息能给你了,最多可以加上日光路径出一张比较炫的分析图,但也没什么用处:
但如果你问一句:这窗户开这么大合理吗?这样排布采光会不会有问题呢?需不需要加设室内灯光呢?
你可以通过一套算法来对室内各个角落的光照度进行计算,但想要更高的效率,就可以把可视化手段派出来——你可以设置好项目位置、时间、天空模型等信息,利用云渲染的功能得到这样的图:

图片左侧是照度分析,右侧是真实渲染,左下角则是照度从暗到明的图例。这张图片背后是一个长长的结构化数据表格,有四列数据,分别是每个点的XYZ坐标值,以及这个点的照度计算值。
但你不需要看到那张表格,甚至不需要知道照度的计算方式,从可视化处理后的图上就能直观的看到什么地方该加窗户,什么地方该加灯。
再举个例子。
Revit会自动给由墙和板封闭起来的区域加上一个叫空间的属性,你可以通过分析板块中的「热负荷和冷负荷」模块,来设置每个空间的功能、人员密度、照明需求、加热和制冷的温度控制等等信息。
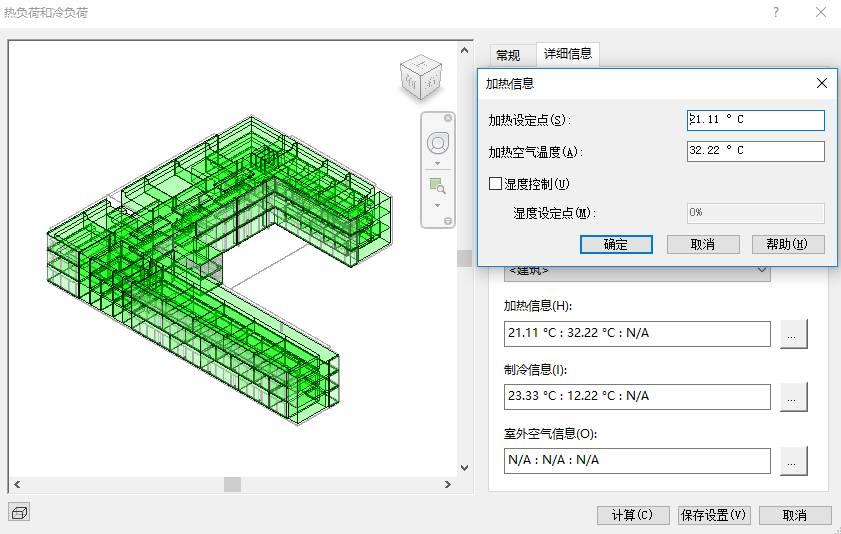
通过这些数据的设置,软件会帮你算出建筑性能分析表,给你一份能耗分析报告,进而帮你优化空间的区分,指导照明和暖通设备的设计。

这种分析、计算、模拟、优化的工作,在传统的工作方式中叫做CAE,它的历史比BIM悠久得多,只不过原先因为CAD软件无法提供它所需要的数据,无法跟设计同步进行,一般都是在整个设计完成后,再用单独的软件来做,达不到指导设计的效果。
而BIM则是把CAE工作整合到设计流程中,把它需要的底层数据直接整合到构件属性里,用关联性来提升了分析模拟的效率。
像Revit这样的软件,有大量把数据加工成信息的功能。这些数据全部都藏在每一个族的族参数里。
比如一个简单的风管族,就有尺寸、风压、摩擦、流量、损耗系数等等几十个参数。
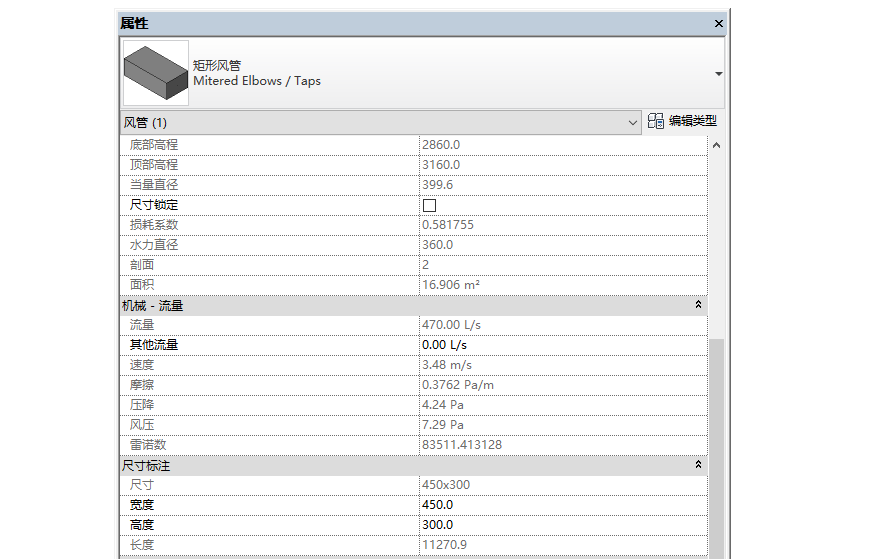
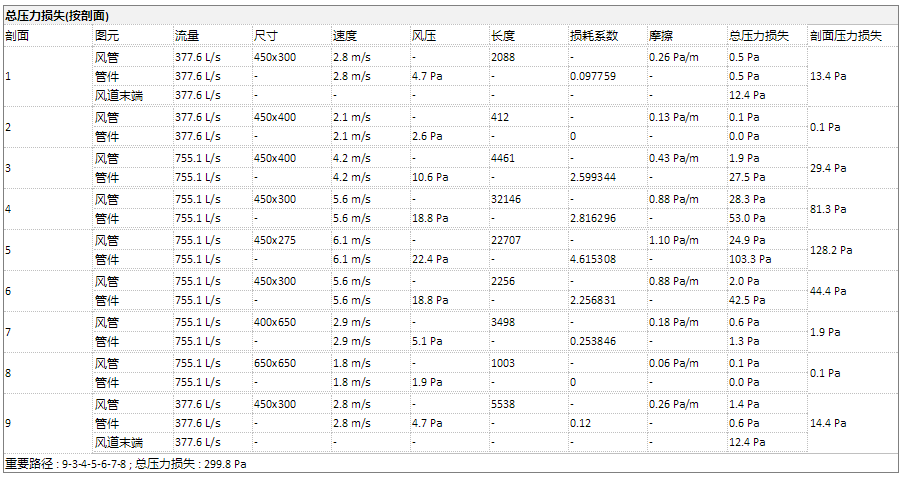
只要是参数,就都可以像之前咱们说的楼层面积一样,进入明细表进行计算,也有一些参数是在加入了风系统之后,和其他构件的参数互相关联进行更高级的计算。
比如你可以查看某一套风系统的压力损失报告,看看自己的风管尺寸是不是合理?是不是拐弯太多了?
可能你觉得这个太复杂了,那咱们换个简单的例子。
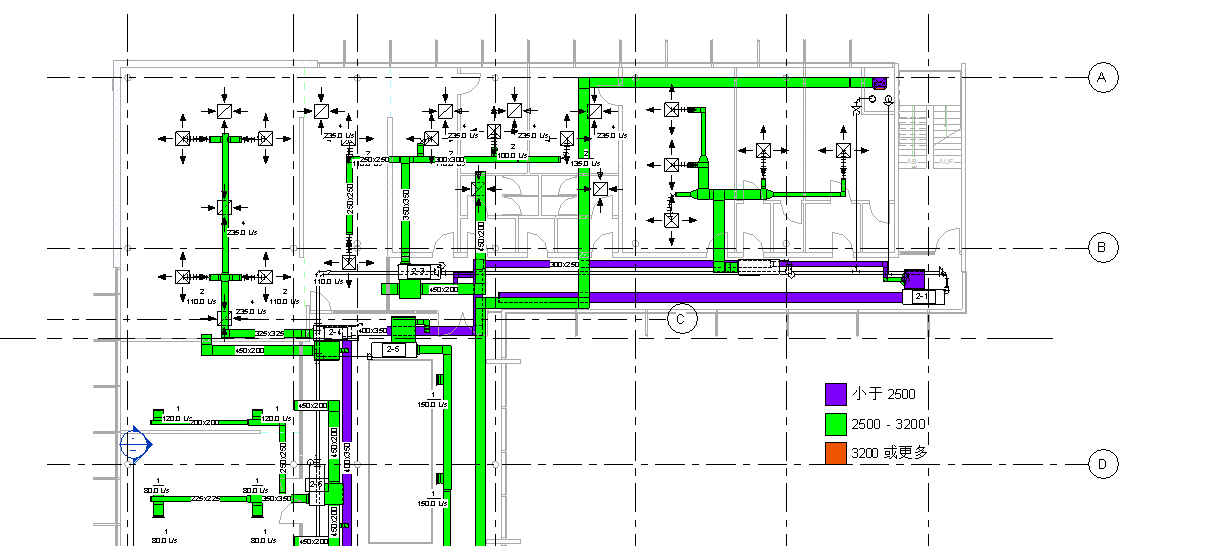
你想问这样一个问题:我画的风管净空是不是都满足要求呢?
想解决这个问题,一个办法就是统计一下风管的高程表,排查有没有净空不满足的情况,不过还有更简单的办法,就是用可视化的手段,给风管加入一个颜色图例,设置好关键高程的数值和颜色:
你看,哪里的风管净高出了问题,是不是一眼就看出来了?
上面这些说到的是设计阶段和深化阶段提出的问题和获得的信息。到了施工阶段,人们提出的问题不一样了,所需要的数据和加工数据的方式自然也就不一样。
比如经常说的5D动画,单独一个动画,实在是没什么用,但动画背后实际上是一个结构化的数据表格,有三维是构件的XYZ坐标,一维是时间信息,一维是成本信息,还有一维是构件的类别信息。
如果你提出这样一个问题:「10轴到12轴的土建部分,在下个月10号之前,需要准备多少资金来买水泥?」
这实际上就和一开始咱们说的支付宝的例子里,「我这个月充了多少手机费?」那个问题一样,只不过需要的数据维度多了几个。这些数据被储存在软件里,可以按照任意的维度进行切割,调出你要的那一部分,变成对你有用的信息。
关于信息该怎么应用的例子还有很多,咱们就不展开一个个说了,它们背后的道理是相通的,来给你总结一下:
➤在BIM模型里,数据以参数的形式存放在最基础的单位——族里面。
➤参数是彼此关联的,你改变了风管的尺寸和走向,那对应风系统的一系列分析结果都会自动跟着变化,这既能提高分析效率,也能帮助你发现错误。
➤结构化是数据成为信息的基础,你看到一切炫酷的应用,背后都只不过是一系列的表格。即使像照明分析功能呈现的是可视化的结果,但背后还是数据表格。
➤不同的人对信息的需求是不一样的,设计师关注分析和计算信息,翻模人员关注空间和形体信息,施工单位关注成本和进度信息,运维单位关注更新和维护信息。不同人的关注点没有高低之分,区别只是需要的数据不同,加工数据的方式不同。
➤无论在哪个环节,数据都躺在模型里,没有任何意义,只有特定的人寻找特定答案的时候,数据才会被整合成信息。比挖掘数据技能更重要的,是提出问题。
目前,国内的现状是模型用的多,信息用的少,原因主要是下面这几点:
1. 创造数据的人,和需要信息的人,往往不是同一批人。
想要得到一张正确的分析表格,至少需要在建模时把相应的族参数设置好,但建模的人不需要这张表格,在没人额外付费的情况下,就不愿意花费更多的成本。
2. 提出问题和找出答案,要付出更多的学习成本。
在上边的例子里你能看到,每一个专业想要得到信息都不是软件自动完成的,需要相关的专业知识match背景才能提出问题,更需要深入的软件学习才能掌握加工数据的方法,这两者都需要花大量的时间。
3. 很多时候人们根本不需要答案。
除非业主或者项目有更高的要求,设计院设计成熟的项目直接套规范就够了,翻模人员照着图作出样子就够了,施工单位凭经验估算就够了。
对于这三点现状,对于行业未来该怎么发展、会怎么发展,BIMBOX今天不做评论,而是把问题留给你,每个人对未来的思考都是不同的,这也决定了每个人走的路各不相同。
今天的话题聊到这儿就结束了,最后是本月的福利送书时间,如果你有兴趣,可以往下看看书里的这个小故事:
英国量子物理学家戴维·多伊奇在读研究生的时候,参观天文系同学的工作。他们研究的是一组1800多张的玻璃负片,恒星和星系在上面呈现为一系列的暗影。

星系在上面的投影实在是太小了,必须拿显微镜才能看清。戴维在显微镜下不停的移动十字叉丝,眼前划过了一个又一个遥远的星系。
在观察某一个星系的时候,戴维突然想到,「我会不会是第一个也是最后一个注意到这个星系的人?」
自己正在看的小黑点,里面有数以十亿计的行星,每颗行星都有自己的季节变换,日升日落。有没有一颗上面有生命呢?会不会也有天文学家,此刻正在观察着我们银河系呢?
戴维对自己的宏大想法有点感动,就抬头问旁边的朋友,这个星系有没有名字?那位朋友看了一眼说,「哦,这个是感光剂上的一个缺陷。」
思维的急剧转换把戴维逗乐了,突然之间,他看到的图像里没有了天文学家,没有了山川河流,没有了亿万个世界,他以为是看到过的最大的物体,却只不过是一臂距离之内的一个微小污点。
戴维又不禁追问自己,等等,我到底有没有看到星系?所有照片上的其他星系,不也都是一个个黑色斑点吗?真正的星系,不是在头顶上方吗?
人眼的能力太有限了,如果抬头仰望星空,尽管你和那些星系之间只隔着几克的空气,你却什么也找不到;而在实验室里,你和真实的星空隔着的,是一台望远镜、一台显微镜、一部相机、一间照片处理室,所有这些人造设备隔在中间,反倒让人把星系团看清楚了。
现在的天文学家从不仰望星空,人造的仪器去观测人眼看不见的信号,然后把它们数字化,用计算机处理和分析,拿到科学家眼前的,早已不是星星本来的样子,而是一大堆数字和表格。
每多一层的物理隔离,就需要更高层的知识才能得到信息。每多一层隔离,对于普通人来说,就离星星本来的样子越远;而对研究人员来说,反倒离事物的本质更接近——他们能看出星系的距离、温度和其他性质。
技术已经深深的改变了我们观察世界的方式——显示屏上的像素,表格里的数字,这些东西在物理上与星系相差甚远,它们不由核动力支配,不曾存在了数十亿年,不能孕育生命,但当天文学家看着这些东西的时候,它们就是恒星。
我们的建筑信息模型,不也正是如此吗?
这本书名字叫做《无穷的开始——世界进步的本源》,它是一本能改变你看待世界方式的好书,我们把它连同另外一份礼物作为本月的粉丝卡福利发放,明天给大家公布获奖人。

这一期就聊到这儿,有态度,有深度,BIMBOX,咱们下次再见!









暂无评论
要发表评论,您必须先 登录