

你好,这里是BIMBOX。
我们之前花了四期的篇幅,给你讲解了BIM的编码是什么,在第四期的最后我们也留了一个尾巴,再给你谈谈国内的建筑信息编码。
之所以间隔了这么久,是因为我们越是了解就越是发现,国内的编码体系很杂、很乱,而且和它相关的,还有设计、施工、运维等业务中存在的问题,有「全生命周期管理」这个理念的大坑,甚至很多环节BIM推进不下去的症结也藏在这个深不见底的黑洞里。
因为我们在讨论「全生命周期」这样的大事时,很少会钻到一个编码的小细节里去,但正是这些细节里的小蚂蚁,一点一点啃出了这条路上的一个个坑。
所以今天我们虽然是继续聊BIM编码,但真正的话题是它背后一系列问题,这些问题导致了各路专家理念的冲突、导致了理论研究和一线操作的割裂。
咱们先简单回顾一下,之前我们四期关于编码的内容都谈了些什么。
编码的存在意义,是人类进入计算机时代,信息在不同语种、不同行业、不同软件之间传递,需要一套统一的二进制规则。
建筑信息编码的重点不在于代码本身,而在于分类,因为不同角色对建筑元素的分类方法是不一样的。投资人和设计师关注建筑的成品物理组件,而施工单位更关注工序的分解、是实现这个物理组件的方法。

到此,咱们算是赶上了进度,前几期文章的链接放到最后,如果你感兴趣可以去看看。
看完了这些知识,你会不会有种感觉:好像除了满足一下好奇心,这些东西知道了也没什么用呀。
你这么想就对了,大多数设计师和工程师,确实是不需要编码知识的,正如我们每天都用键盘打字,却根本不需要知道汉字背后的UTF-8和GB编码规则一样。这些编码已经由你使用的软件编写好,你在前端使用功能时,对编码应该是无感的。
不过,这里用文字编码来打比方,有个很大的问题。文字的编码历史中,先后出现了ASCII、GB、Unicode、UTF等等不同的编码,人们都是选择「当前最好的编码」,而不是等一个完美的编码。
时至今日,我们能使用各种文本软件而不需要操心编码的问题,正是因为文字编码的迭代已经基本完成,全球大一统都没啥问题了。而我们的建筑编码,还远远没达到这一步,我们还是活在编码不断更替、不断竞争的时代里,我们所使用的软件自带的功能,也还远远没达到业务的要求。
所以在有些情况下,人们还是要求助于编码,有时候是自己编,有时候是抄现成的。
咱们先举几个例子,来看看他们为什么要用编码,再回来看一个大问题:不同的人说建筑系信息编码,有时候根本不是一个意思。
案例一
之前我们的一位朋友@段晨光,谈到他在参与法兰克福一个大型项目时的案例。其中一项很重要的工作,就是把机电专业在墙和楼板上预留的洞口在建筑模型上表达出来,这样建筑师才能出正式的施工图。
这里的难点在于,机电工程师用的软件是 Tricad,而建筑师用的 Revit。这些洞口还不是一次性挪过去就行,每一层建筑都需要前后开几次会才能把洞口位置确定下来。整个项目下来,洞口转移的过程需要重复将近1000次。
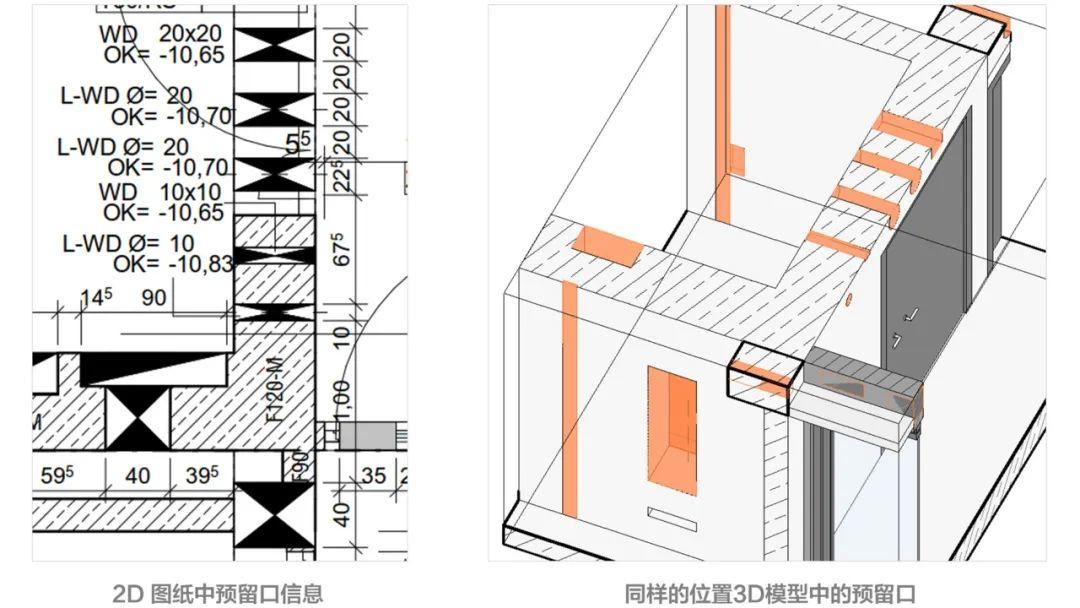
为了增加这项重复劳动的效率,甲方就组织第三方公司开发了专门的插件,它能把机电工程师提交的 Tricad 洞口数据批量转化成 Revit 族,这些族还必须带着自己的空间坐标信息,才能在导入 Revit 的时候,自动放到该呆的地方去。

这样的批量导入工作还不够,因为机电工程师设计过程中可能会犯错,每次开完会,一部分洞口的位置也需要重新调整,如果每次导入都需要一个一个洞口检查位置,那工作量还是太大了。
所以这个插件还开发了一个功能,就是利用一串编码来跟踪每一个洞口。它在 Tricad 里编号为3519621,到了 Revit 里也必须编号为 3519621,每一次移动了这个洞口的位置,它的编号还必须保持不变。
这样,每次导入的时候,它们就只需要追踪那些编号一致、空间坐标发生变化的洞口,也就是下面图中紫色的部分,看看是工程师弄错了,还是洞口的位置发生变化了。

下面是重点了:我们知道 Revit 每个构件都有一个独立的 ID,那我们能不能用这个 ID 号作为洞口的编码呢?毕竟,这样用现成的话我们就不需要专门为它设计一个编码了。
答案是:不行。
因为 Revit 和 Tricad 用的不是一套计算机编码体系,它们之间的构件 ID 是不一样的。所以一个洞口必须有一个软件自带编码之外的、额外的参数,我们还要在插件上设计一个规则,让这个参数能从 Tricad 里出去,再完好无损地进入到 Revit 里面去。
这就是我们第一个案例代表的一种情况:当我们在不同软件里传递一个信息的时候,光靠软件自带的构件ID编码是不够的。我们必须在它们之间创造一把「钥匙」。

案例二
我们的另一位朋友@金戈也谈到了他在项目服务中使用编码的原因。
他所在公司的服务对象是业主方,对方要的东西很明确,不是设计模型,也不是施工模型,而是竣工模型。
甲方要求,在竣工模型的构件里,要加入他们运维需要的属性信息,这些属性包括技术信息,比如长度、宽度、高度、风量、水量等;也包括非技术信息,比如设计人员、施工人员、维保人员、工艺工法、控制开关、联系电话等,加起来要写70多个参数。

这些参数如果要一个一个手动填写到 Revit 模型构件里,那是要累出人命的。所以金戈的团队选择了数模分离的方法:在 Excel 里批量编辑这些参数,然后把它们批量导入到 Revit 里,附着到每个构件上。
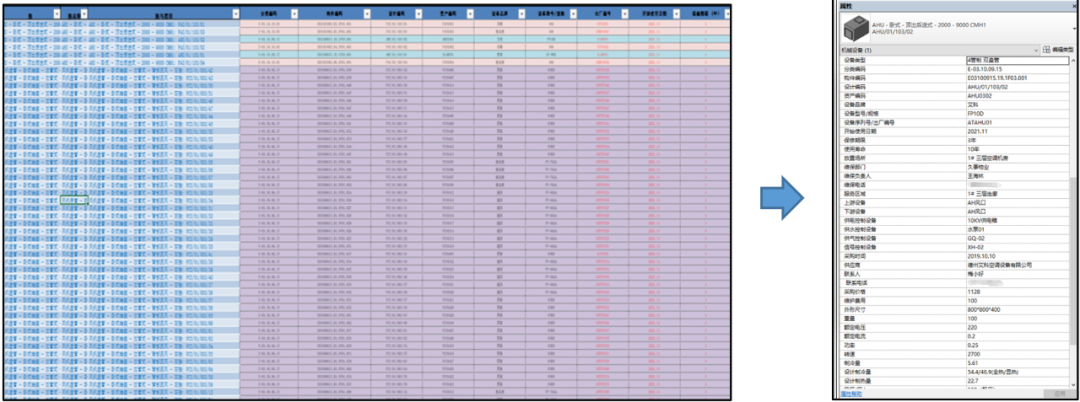
要达到这个目的,在 Excel 和 Revit 之间,就必须有一把钥匙,这和前面说到的 Tricad 和 Revit 之间互传信息是一样的,只不过这次要传输的不仅是空间坐标信息,而是70多项参数。
那么,我们还是像上个案例那样,给每个构件设计唯一的编号,让它作为 Excel 和 Revit 之间的「钥匙」呢?
答案是:不行。
因为上一个案例要处理的只有一种构件类别,也就是洞口,也就不需要分类了,只要每个构件的编码不重复、可以被不同软件识别就行。但在这个案例中,工程项目的交付文件里有成千上万个不同种类的构件,如果每个构件都彼此独立,那 Excel 表格可就要写得无限长了。所以必须要分类。
你可能会说,要分类这很简单呀, Revit 不是按照墙梁柱板水暖电给分好类了吗?跟着分类走不就行了?
还是不行。
这里的关键在于,不同人关注的构件分类不一样。
拿水泵这个构件来举个例子。设计师在做设计的时候,会根据专业,把空调水泵、给排水水泵、暖通水泵给区分开,它们的分类是跟着专业走的;到了施工那里,算量要按照清单分类来分,工序则要按照分部分项来分;而最终到了业主那里,水泵就是一个资产,不管它在设计的时候属于什么专业,也不管它安装的时候在哪个工序。

同样一个东西,在设计阶段可能归属于某种分类,在施工和运维阶段可能会归属于另外不同的分类。而 Revit 是为设计服务的软件,如果你的成果服务于运维,它自带的编码系统就难以满足需求,而要在这之外重新设计一套符合运维标准的编码规则。
在金戈所在的项目里,最终交付的是业主要的竣工模型,而且参与项目的还不止他们一家,所有服务商最终交付的结果要汇总到业主这里,大家写参数的办法可以各显神通,但最终那把「钥匙」必须是统一的。
最终这个项目,甲方召集各方开会,金戈团队牵头,编一个大家都同意的编码规则,各家再把这个规则里的编码作为「钥匙」,写到交付的模型里去。
下面这串代码,就是站在甲方的视角来看待一个离心风机的结果,显然,通过分类、规格、位置和序列号能定义一个构件的唯一性,剩下的就是往里挪参数了。

聊到这儿,咱们稍微总结一下,大多数时候,我们建一个模型交出去,或者出几张图、算算量,是完全不需要考虑编码这件事的,软件本身已经帮你编过码了。但在以下几种情况下,我们就需要自己定义编码了:
➤ 需要软件自带功能无法实现的自动批量操作
➤ 需要在多个软件之间传递数据
➤ 需要在多种数据类型之间传递数据
咱们说完了大家为什么要用编码,接下来再说说:当人们争论编码的时候,很可能说的不是一件事。
你看,在第一个案例里,我们要实现的是让每个洞口都能被 Revit 识别并且记住,那就需要给它们设置不同的代码。给每个洞口设置唯一的代码这个行为,有人把它称为「编码」,而也有一些人认为这不应该叫编码,而应该只叫「编号」,因为它只要有唯一性就可以,而不需要遵循某个特定的规则。
在第二个案例里,我们不仅要让每个构件唯一,还需要把它们进一步分类,有的人就说,有分类规则的编码,才叫编码。
还没完,第二个案例中的编码规则是有明确边界的,只能给业主服务,甚至只能给一家业主服务,到了其他人那,这套编码规则就得换。所以又有人说,这种编码不能用于从设计到运维的各个环节,不能叫编码。我们要做一套可以囊括所有信息、用于全生命周期管理的建筑信息编码。
你看,「编码」就是这么两个字,每个人说出来的时候想的东西很可能不一样,咱们可以非官方地把这三种编码分别叫做「构件编号」、「分类编码」和「全过程信息编码」。
在这三种讨论里,前两种情况咱们说过了,接下来说说第三种情况:我们能不能编一个终极编码规则,让所有项目、所有人都适用呢?如果能,实现的难点在哪里呢?
很多人谈到编码的时候,喜欢用身份证举例,那咱们就用身份证来说明这个问题。
每个人的身份证号都是不一样的,它实现了每个人身份的唯一性,这一层不用多解释了。
再进一层,身份证号码除了唯一性,还是可以携带一些信息的。
比如目前用得最多的18位身份证号码,你可以通过前六位数字定位一个人的籍贯所在地,从第7位开始可以知道一个人的出生年月日,进而可以计算出年龄;倒数第二位则可以看出性别来。

如果现在需要设计一个程序,对大量人员进行统计、管控,只需要把他们的身份证号输入进去,再设置一定的过滤条件就行了,比如统计河南省有多少大于40岁的男性。
上面说的是事实,下面为了说明问题,我们做一些假设。
假设疫情过后,国家有关部门想给每个人加上一个「有没有被传染过」的信息,1代表传染过,0代表没被传染过。那能不能往身份证号后面加一位数字呢?当然,理论上是可以的。
这样每个人的身份证号就变成了19位。我们能用身份证号信息做的事就多了一个维度,可以统计每个省市不同年龄、不同性别的传染分布了,很方便对不对?
可是没过几天,教育部的人又说,那不如把学历也编个号,写到身份证号里去吧。于是身份证号又变成了20位。
接下来的事你想想也知道了,很快,找来的部门越来越多,身份证号越来越长,没过几年,每个人的身份证号都变成2000位的了,出门像带个扁担一样,这就不合适了吧?

还有另外一个问题,就是有些东西是随时间不断变化的,比如你想把一个人的职业、收入、胖瘦这些东西也让计算机读取,可它们今年和去年的数值是不一样的,总不能每隔几个月就换一个身份证号吧?
所以你看,虽然在理论上我们能把一切信息编码,但在真实的世界里,要把所有信息全都储存在一个「大一统」的编码框架里,也许并不是一个好主意。
真实世界里的一个身份证号,能起到的作用主要还是唯一性,具体要查看一个人的职业、健康、社保、学历等信息,是以这串唯一的编号作为「钥匙」,进入到其他表格里才能查到。
我们给建筑构件编码,也必须是这样:先通过某种比较粗略的分类方法给构件分类,赋予一串唯一不重复的编码,然后把每个阶段需要的数据单独存放到族信息、数据库或者表格里。
到了这一步,争议还没有结束。
目前的现实情况是,不同构件在设计阶段按专业分类、施工阶段按流水分类、运维阶段按资产分类,每一拨人关注的信息要分别装到不同的篮子里。
甚至对于同一个构件的同一个属性,大家的需求都不一样。比如同样是「材质」这个参数,做装修的人可能关注它的纹理图案,做绿色建筑分析的人可能关注它的保温性能,施工方可能关注它的工艺流程,甲方可能关注它的价格成本。
原本,大家用各自的软件,带着各自的编码,边界清晰, 没出现什么问题。
可一旦说到「建筑全生命周期管理」这样的词,问题就来了:大家各自使用的模型、数据库、Excel,计算机程序是不能随意互相访问的。
比如某一家企业,把一根柱子编号为A-01,它的属性信息单独存放在一张资产运维表,表格被命名为CE01。只要到这张表格的第4列就能查到它的材质信息。
这家企业制定这样的规则,可没和全行业的人打招呼,另一家企业用其他软件打开这个文件,A-01是啥不知道,CE01是哪张表也不知道,这就没法查了。
在一次线下交流会上,一位BIMer向广联达的一位技术人员提问:为什么用图形算量服务在施工阶段总是很别扭?对方回答:因为图形算量软件是给招投标用的,本来就不是面向施工来设计的。而招标算量和施工算量的业务有很多不同。
➤ 算量依据不一样,招投标阶段是国家和地方的清单计价量,施工阶段是实物量;
➤ 构件分类不一样,招投标阶段构造柱不用细分,施工阶段还要按部位和流水段细分;
其实类似这样的问题很多,而我们真正应该深究的,不是去问为什么用于招投标的模型不能用于施工算量,而是要反过来问:我们为什么需要招投标模型能用于施工算量?
因为我们每天都听到全生命周期管理,听到信息的上下游传递,听到一模多用,我们误把愿景当成了现实。
而现实世界是这样的:编码是给软件用的,每个软件一定有自己的编码体系。但软件开发出来是要有人买单的,软件开发的所有目标,就是满足买单者的业务要求。
软件的服务边界处可能会有一点点模糊的外扩,比如支持一些中间格式的导入导出,但一定不能无限外扩,否则无限穷举的研发成本会把一个软件商拖垮。
那有没有可能有行业里的其他参与方来做这件事呢?答案是有。
咱们拿大家都熟悉的三国来打个比方,简单说说三方在做的事:
魏国
名正言顺占天时
这一方最有代表性的就是中国建筑标准设计院。
标准院很早就拿到了尚方宝剑,组织行业专家出一本适用于整个行业的建筑信息编码标准。工作起步时国内没什么可以参考,主要就是参考了美国的 Omniclass来做本地化。可是这工作做了四年多,却一直压着没有发,因为一直不知道这本标准发出去给谁贯宣交底,谁来用呢?直到2017年马上要到五年期限,这才硬着头皮把这本《建筑工程设计信息模型分类和编码标准》发出来。
这一方目前的局势是:Omniclass 在国外没有解决的问题,它也尚未解决,而 Omniclass 有 Revit原生加持,好歹落了户,可国内这本标准很少有人直接使用,GB/T的身份也没能「挟天子以令诸侯」。

这一方的代表就是黄强先生带领的中国BIM发展联盟。
从P-BIM到CDM,黄强想做的事情是独立于任何软件之外的一套标准,一个编码对应一张表,数据必须能让现场一线人员编辑。之所以这么做,还是因为一线工程师的很多业务需求找不到现成好用的软件来解决,软件之间的数据打通也一直是猴年马月的事,数字工程师的探索不能等,那就招呼工程师们自己搞数据标准。
这一方目前的局势是:不管外界有怎样的评价,确实有一群工程师在这套方法中看到希望,甘愿奉献出时间来写这套标准。不过也存在着标准写出来之后,有多少软件商愿意使用的问题。

吴国 财大气粗占地利
这一方面最有代表性的就是万达和华东院这样的超大规模企业。它们有自己一套详细的编码标准,这套体系已经打破了设计、施工和运维之间的壁垒。
万达要求凡是来提供服务的,必须用万达的平台,用万达写好编码属性的族库,遵循万达的标准来交付;华东院则是基于 Bentley 系列软件无缝交换数据的特点,投入重金开发了自己的一套软件和平台体系,把所有数据壁垒都在内部消化掉。据说这两家企业在信息化方面的投入都已经过亿。
这一方目前的局势是:打破了软件和业务之间的边界,但同时建立了自身服务的边界,万达的系统做不了碧桂园的项目,华东院的在雄安交付结果也用不到湖南。

在这里需要加粗强调:上面三国的比喻只是为了帮你理解三个不同的探索方向,国内探索的「诸侯」也不止这三方。BIMBOX没有资格、也无意对任何一方的付出提出批评或质疑。
未来还很长,人们努力到最后其实不仅仅是技术问题,也有话语权的问题。一个全行业普适的标准,肯定不是在某个早晨突然让所有人达成共识,而是通过某一个方向日以继夜地持续探索,一个项目一个项目、一个软件一个软件、一拨人一拨人地争取过来。
我们所在的世界不是一个纯技术的世界,这个世界之所以是今天的样子,还有很多商业的、资本的、甚至政治、人文的原因。
在和我们的朋友@林臻哲聊到编码问题的时候,他说:
“现阶段务实的企业不应该盲目追求编码,而应该明晰自己业务对象的边界。给谁提供服务,就按需交付。
尤其是对于现阶段BIM在设计和施工的发展情况来说,首先要解决的根本不是编码的问题,而是标签的规范问题。
所谓标签,你可以理解为 Revit 里任何参数的命名。我们要给一堵墙编码,如果在内部光是「现浇」、「浇筑」、「混凝土浇筑」这些属性标签都无法统一,那任何编码都是没意义的。
这让我想起在做《中国BIM草根报告》调研时候发生的一件糗事:我们写了一道问题,让大家回答自己常用的BIM软件,给的是简答题,拿到问卷我们就傻了,光是Navisworks一个软件愣是有20多种写法,这咋统计呀?
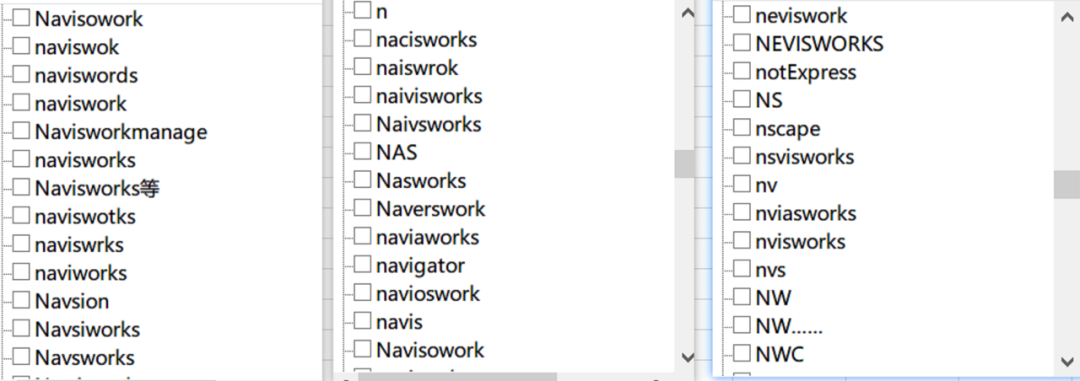
我们还处在一个莽荒的时代,未来的建筑信息编码无论怎么发展,一定是被软件集成在后端,使用的人对代码应该是无感的。
这就像早些年大家寄东西,都要自己写邮编,方便邮局的机器识别代码、实现自动分拣。后来人们发快递不需要查邮编了,用下拉菜单选择就更不容易出错。再到今天,连下拉菜单都不需要,你只要复制粘贴一下,软件就会自动帮你把地址、人名和电话分类填好。
人本就应该处理自然语言,编码本就应该属于计算机。只不过我们这个行业和那个「去邮编」的美好世界之间,还隔着很多大坑。
但我们相信,看到坑的愁眉苦脸,总好过假装没有坑的歌舞升平。
在和@小耳朵猫酱一起探讨这一期内容时,我开玩笑道:这个系列写了好几万字,感觉绕了一个大圈,告诉大家这有一个坑。她这样和我说:
它不是一个坑,它只是还没填平的路。

这一期咱们就聊到这儿,有态度,有深度,BIMBOX,咱们下次见!
特别答谢在这段时间帮助我们提供案例和思路的:商丽梅、吕振、段晨光、金戈、戴路、王初翀(小耳朵猫酱)、林臻哲。
—我是精彩回顾分割线—








这个系列写的非常好,拜读了!什么时候介绍一下Uniclass呢?